Adding Value 32 times a week - 2 years of Continuous Deployment to Production
Published: 2019-08-01 by Lars experiencedelivery
(Note: this is cross-posted from Triggerz Engineering Blog)
Introduction
If you are on a software team who would like to try Continuous Delivery or have just started, this blog post is for you!
As a software team, how quickly can you safely get a bug fix released to users impacted by the bug? How quickly can you safely get a new feature into the hands of users for them to reap the value of new capabilities?
At Triggerz we believe in fast feedback. We have been doing Continuous Deployment to our production environment since the very first line of code was written 3 years ago. We have continued to do so through the two years we have had paying customers and users.
So how has this been working for us? What does Continuous Deployment look like in practice? Learn more in this blog post.
How quick - How safe
Wikipedia defines Continuous Deployment and Continuous Delivery as:
Continuous Deployment is a software engineering approach in which software functionalities are delivered frequently through automated deployments.
Continuous Deployment contrasts with Continuous Delivery, a similar approach in which software functionalities are also frequently delivered and deemed to be potentially capable of being deployed but are actually not deployed [yet].
So Continuous Deployment is a kind of Continuous Delivery where software is not just made continuously available for deployment but is actually continuously deployed.
At Triggerz we use Continuous Deployment by frequently deploying new versions of our software to our production servers. Whenever a team member pushes a change to our source code repository, our Continuous Integration server picks up the change, runs a number of tests and if successful deploys the new software. This is a fully automated process and takes place on average 32 times a week. Verification and deployment takes a total of 20 minutes.
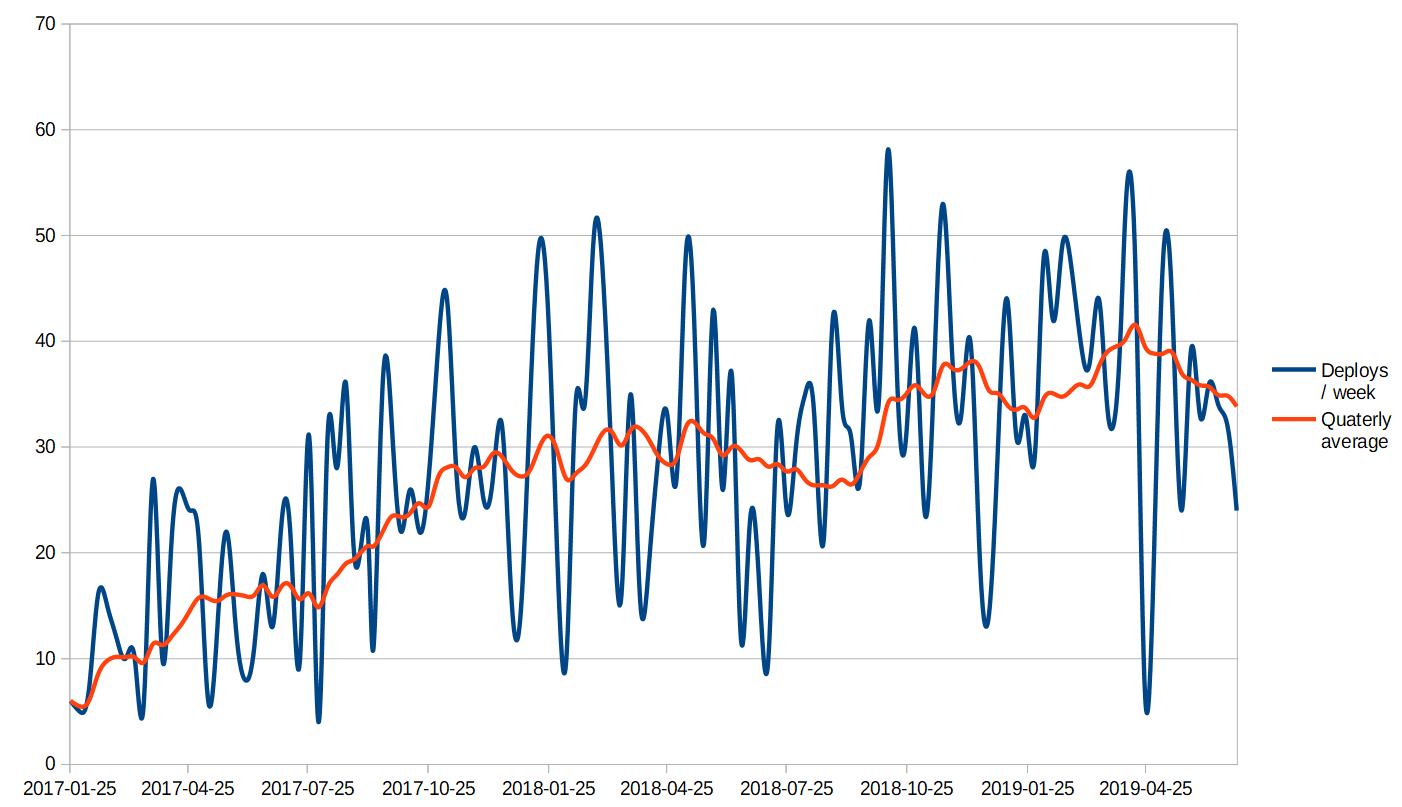
In general this is a very robust and safe process which almost never requires any form of intervention from the engineering team. The engineers can focus on the requirements at hand and how to best implement software to satisfy them.
We manage the release of new features with run-time feature flags. So while a new feature might technically be deployed, it might be released to users only some time later. We do this primarily to manage customer expectations.
We do have occasional hiccups. We strive to avoid them, and we usually try to fix not just the immediate issue but also the root cause. This means that whenever we do have an issue it is almost always of a type we have not seen before. We have tracked all production issues since we launched two years ago, and have divided production issues into 4 categories: downtime, multiple-user, single-user and impactless.
- downtime issues disrupt all users
- multiple-user issues typically disrupt many users,
- single-user issues impact just a single user and
- impactless issues are fixed before any users were impacted.
Over the past 2 years we have had 15 downtime issues, 46 multiple-user issues, 100 single-user issues and 50 impactless issues. So about 1 in 60 deploys (i.e. twice a month) have serious unintended consequences for one or more customers and about 1 in 15 deploys (i.e. twice a week) have minor or no unintended consequences.
Only 25% of our total downtime was caused by changes we made ourselves. Downtime is mostly a result of disruption on the internet in general or with a specific service that we depend on. During the past 2 years we have been down for a total of 8 hours and 50 minutes, giving us an uptime of 3 nines: 99.94%.
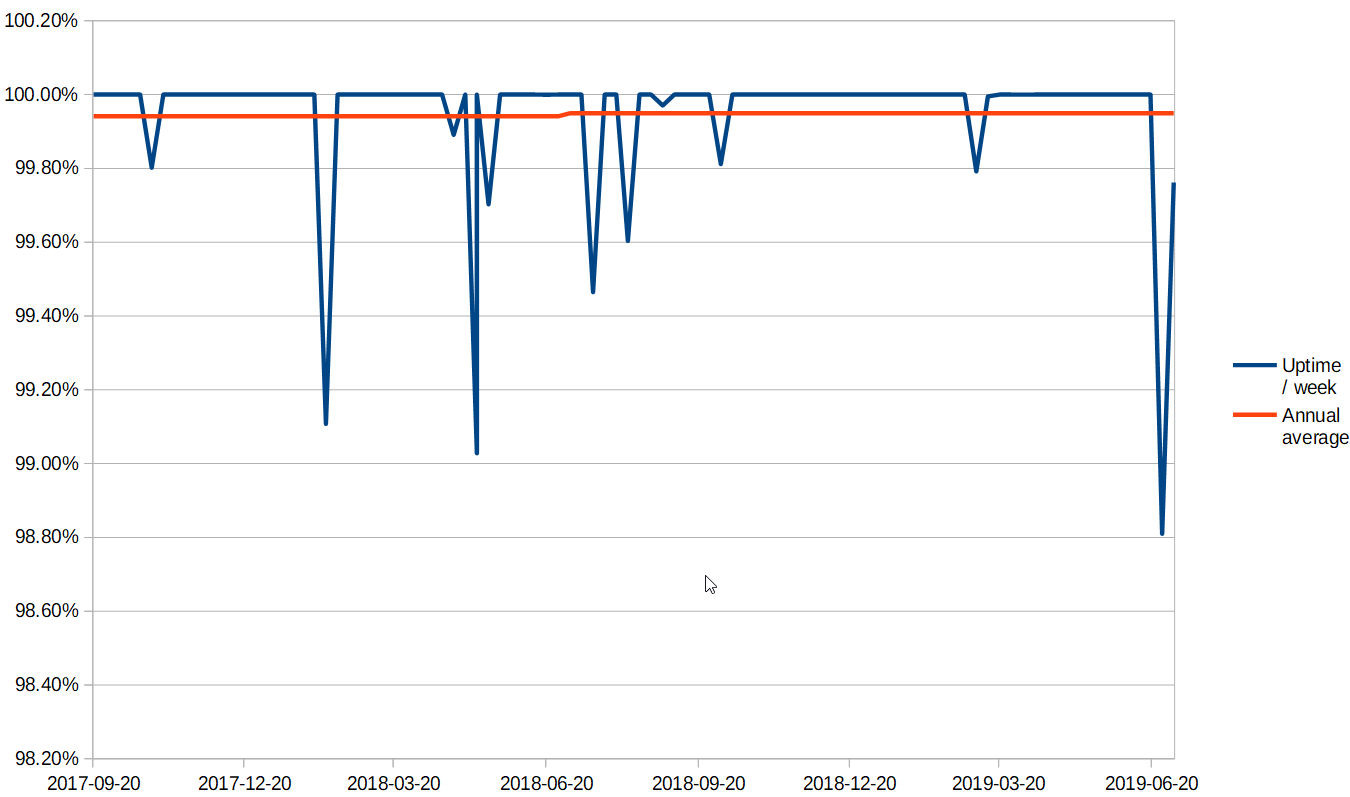
We are logging all run-time errors, and the engineering team is immediately notified. This causes most unintended consequences to be discovered and fixed before being reported by any users. Issues are usually fixed within a few hours, regardless of category.
While one could argue that some of these unintended consequences happen only because of our Continuous Deployment, the fact that we can fix them so quickly is also due to Continuous Deployment.
How do customers like it
Most of our users never experience any issues or downtime, and compared to other vendors we generally have a good reputation with our customers. A benefit that is also appreciated by our customers is that they are able to receive fixes and improvements very quickly compared to other vendors who often take weeks or months to deliver.
During our sales process, we do sometimes struggle to convince prospective customers that Continuous Delivery is at least as robust as the alternatives. Continuous Delivery is still somewhat rare among enterprise solutions, and IT-departments often question us quite a bit before they are comfortable enough with our approach.
How to make it quick and safe
An important prerequisite to delivering continuously is to have extensive and effective automated tests. We want to make sure that a software change did not break any existing functionality and that any new behavior is verified by new tests.
We write automated tests for all our production code: front-end, back-end and database-level. Even though code coverage is only a crude metric for test quality, it is easy to measure and we track it continuously to be alerted when it drops. Our tests currently cover more than 90% of our code (JavaScript statements). We have fixed code-coverage thresholds per module that will also alert us to missing or disabled tests.
When an issue does occur, we investigate the root cause and it is usually easy to find the specific commit that was the direct cause of the issue. In addition, we will often find that the issue could have been prevented by a test case which is missing for some existing related code. As a team we are very aware of our shared responsiblity for the safety net provided by our tests. If a developer feels like cutting a corner by skipping some tests, they know that this will eventually come back and bite some of their colleagues.
We have 1.3 times as much test code as production code. Our tests are mostly isolated unit-tests testing single components or modules. In addition we mock test data automatically by capturing API exchanges, which means that our tests act as true integration tests while at the same time being very fast. For example, running our 1383 front-end tests takes 4 seconds on a developer laptop. Read more about auto-mocking here. We also do automated cross-browser-testing by running all our front-end unit tests on various browsers, operating systems and devices. And finally we do have a few automated end-to-end tests testing through the real UI in a real browser against a real database.
Our extensive set of automated tests works well for ensuring that existing behavior has not regressed. To hunt for unforeseen issues while developing new features we also test those manually often by someone else than the developer. We are able to do this manual testing in production before releasing the new feature to users, usually by hiding the feature behind a run-time feature flag.
We have one final safety-measure that has saved us a few times: rolling deploys, which is an AWS Elastic Beanstalk feature. We have multiple app-servers and our deployment script will take down a subset of those for first round deploy, and verify that they start properly before adding them back into the cluster and deploy to the remaining servers. If the initial subset deploy fails, they will roll back to the version previously installed.
Changes to the database schema, such as new columns, tables or indexes, need to be deployed separately from application servers to ensure that there is no downtime. A schema change must work with the currently deployed version, so more complicated changes must sometimes be split across multiple deploys (so for example instead of simply renaming a column in one step we will do three steps: 1. add a new column and synchronize data, 2. change code to use new column instead of old column, 3. remove old column). Keeping schema changes isolated from code changes also ensures that the schema change is properly validated by all the existing tests before being deployed to the production database server.
When to roll back
When we become aware of an issue after the change was deployed we usually have two options: 1) we can revert the change or 2) we can fix the issue with a new change on top of the faulty one.
Code changes can be reverted creating a revert-commit of the changes since the previous deploy. This is very easy to do with our source repository, and the revert will then be pushed, go through the usual validation, and be live within 20 minutes.
Database changes cannot be reverted in the same way. Instead we always create an "undo"-script to go with every database change, and to revert a database change we will have to manually run the "undo"-script against the production database.
However, we very rarely revert our changes. It almost always feels safer and easier to create a fix for the issue and roll forward with the fix.
How to build it
The tools you need for a succesful Continuous Delivery setup depend a lot on the platform you develop for, whether it is embedded devices, native mobile apps, web applications, distributed services or native desktop applications.
Even for web applications like Triggerz there are differences between different technology stacks. At Triggerz we build software using JavaScript, CSS and SQL, running Node.js on our application servers and PostgreSQL on our database server. In general, we strive to use well-tested tools rather than the latest fancy innovations and we are quite happy with the tools that we use. If we were to start over today we might end up with a slightly different selection, but we do not currently have any plans to switch to something else. The appendix below lists the tools we currently use for our Continuous Delivery setup, including a few tools built in-house.
Conclusion
Continuous Deployment is a very effective approach for us. Introducing Continuous Deployment was easy because we did it from the very beginning. We keep doing it because it provides great value for our customers, fast feedback and low maintenance for the engineering team, and usually 100% hassle-free deployments for everyone.
If you consider trying out Continuous Delivery we can only recommend it, and we hope you can benefit from some of our experiences. Enjoy!
Appendix: the tools we use
- Build
- Test
- Deploy
- Knex - SQL migrations
- AWS Elastic Beanstalk with AWS CLI - app server hosting
- Run-time
- Cryptex - secret protection
- Feature toggles (in-house)