Unit test i den virkelige verden (in Danish)
Publiceret 01/06-2004 af Lars testing
Opsummering
I denne artikel tager jeg fat på de udfordringer vi møder, når vi giver os til at anvende automatiseret unit test på virkelige projekter. Det går ikke altid så let som man får indtryk af fra lærebøger og artikler. Besværlige vilkår i form af databaser, andre eksterne systemer, hardware, brugergrænseflader, tråde og manglende testframeworks kan få nogen til at overveje at klare sig med tidskrævende, manuel test.
I denne artikel gennemgår jeg udfordringerne og præsenterer gode løsninger som har fungeret på virkelige projekter; forskellige projekter som jeg har arbejdet på gennem de sidste 10 år som udvikler eller rådgiver.
Indholdsfortegnelse
- Indledning
- Grundlæggende unit test
- Afhængighed af andre units
- Afhængighed til databaser
- Afhængighed til eksterne systemer
- Afhængighed til specifik hardware
- Test af brugergrænseflade
- Eksisterende kode
- Test af multithreaded units
- Refaktorering af testprogrammer
- Skriv dit eget testframework
- Henvisninger
- Sammenfatning
Indledning
Hvorfor er testautomatisering godt?
Lad mig starte med at opsummere hvorfor det er nyttigt med automatiserede unit tests, der bliver afviklet dagligt.
Mere effektiv udvikling: Når vi skal rette en fejl betyder det som regel meget om fejlen er blevet introduceret i koden for nylig eller for lang tid siden. Når det er lang tid siden fejlen blev introduceret betyder det at ingen af udviklerne i teamet længere har den pågældende del af koden i frisk erindring. Det tager lang tid at finde frem til hvor i koden fejlen opstår, og det tager også ofte lang tid at sætte sig så meget ind i den pågældende kode at vi kan se hvordan rettelsen skal foretages.
Men når jeg har en unit test, der fejler 2 minutter efter at jeg har introduceret fejlen i koden, så tager det som regel kun et øjeblik at indse hvad jeg skrev forkert og rette fejlen. På denne måde spares der vældig meget tid.
Mere langtidsholdbar kode: På udviklingsprojekter, hvor man ikke anvender automatiseret unit test, oplever man ofte at vigtige dele af koden bliver vanskeligere og tilsidst nærmest umulige at vedligeholde. Det kan fx være centrale beregningsrutiner eller datastrukturer som i tidens løb er blevet ændret og udvidet i takt med at systemet skulle leve op til nye krav. Patch på patch har med tiden gjort at udviklerne undgår at pille mere end højst nødvendigt i disse vigtige dele af koden. For udviklerne har en fornemmelse af at koden lige nu virker nogenlunde som den skal, og de ved at en omskrivning vil tage evigheder før alting atter fungerer som det plejer.
Men sådan er det ikke når vi har en række unit tests for de pågældende kodedele. For her kan vi få at vide om den aktuelle kode fungerer ved at køre alle test cases. Så vi kan splitte de centrale kodedele fuldkommen ad og samle dem igen i et nyt design, og når alle test cases kører fejlfrit igennem, så har vi nye og fungerende kodedele, som på grund af deres nye design kan videreudvikles i lang tid fremover. Unit testen gør refaktorering til en overkommelig opgave, og refaktorering sikrer koden et langt og sundt liv.
Bedre dokumentation af koden: Når vi skal skrive noget kode, der skal benytte en eksisterende komponent, så har vi som regel glæde af at se på dokumentationen for den pågældende komponent: Hvilke initialiseringer skal der foretages? Hvilke parametre tager funktionen? Hvordan ser resultatet ud? Hvis vi er heldige findes der kommentarer til den eksisterende komponent, der beskriver disse ting. Måske er kommentarerne endda skrevet på en sådan måde at de danner grundlag for et samlet katalog, som vi let kan slå dokumentationen op i. Og hvis vi er rigtig heldige er dokumentationen endda korrekt... Problemet med denne type dokumentation er nemlig at vi ikke kan få testet automatisk om den er korrekt. Og ofte bliver dokumentationen ikke vedligeholdt i samme tempo som den kode den forsøger at beskrive, og så opstår der uoverensstemmelser og mangler som kan forvirre de udviklere der skal bruge dokumentationen.
Her kan en samling test cases udgøre et nyttigt supplement. En test case beskriver nemlig også hvilke initialiseringer der skal foretages, hvilke parametre funktionen tager, og hvordan resultatet ser ud. Test casen beskriver ganske vist disse ting i form af et konkret eksempel på et kald, og ikke i generelle vendinger som dokumentationen typisk gør. Men alligevel er det tit let for en anden udvikler at læse sig til disse vigtige oplysninger ud fra test casen. Og her er fidusen at disse oplysninger er garanteret korrekte: For vi ved at disse test cases, sammen med alle de andre, er blevet kørt senest i nat uden at fejle.
Bedre projektstyring: Enhver projektleder kender til dilemmaet med at spørge en udvikler hvordan det går med udviklingen af en given feature. Udvikleren svarer: "Ja, den feature er jeg næsten færdig med". Og projektlederens erfaring fortæller ham at "næsten færdig" kan betyde alt mellem 10% og 90% færdig.
Hvis udvikleren skriver test cases samtidig med at featuren bliver implementeret, kan projektlederen i stedet kigge på hvor mange af disse test cases der kørte fejlfrit igennem i nat, og derudfra få et langt mere præcist billede af hvor meget der mangler før denne feature er helt færdig.
Færre fejl: De fleste testere har prøvet at arbejde på projekter hvor det meste af deres tid gik med at gennemløbe en grundtest hver gang udviklerne afleverede en ny version, så helt grundlæggende fejl kunne bliver rettet med det samme. Ofte kommer disse grundtests til at tage en stor del af testernes tid, for ikke at tale om deres tålmodighed: det er ikke specielt inspirerende at gennemløbe den samme grundtest igen og igen dag ud og dag ind.
En stor del af besparelsen i automatiseret unit test kommer af at vi får automatiseret grundtesten. Automatisering af arbejdsgange er ofte hvad softwareudviklere lever af at gøre for deres kunder, og her er der en oplagt chance for at anvende metoden på egne arbejdsgange. Besparelsen giver testerne tid til at foretage en mere grundig test ud i hjørnerne af ny funktionalitet. Det betyder at spidsfindige fejl når at blive fundet af testerne, og at brugerne dermed oplever et produkt med færre fejl.
Tilsammen opvejer alle disse fordele som regel den investering, der lægges i at automatisere unit testen.
Hvordan automatiserer vi testen?
Når jeg starter på et nyt projekt, sørger jeg for at følgende grundlæggende elementer er på plads:
Brug et framework: Vi skal sikre os at testprogrammer skrives på en standardiseret måde. Dette er nemlig en forudsætning for at vi kan afvikle alle testprogrammer automatisk hver nat, og det gør det også væsentlig lettere for den enkelte udvikle at afvikle testprogrammer ad hoc. Vi skal derfor vælge et framework der matcher vores udviklingsplatform. Eksempler på udbredte frameworks er JUnit, CppUnit, NUnit. Hvis der ikke findes et tilgængeligt framework til vores udviklingsplatform kan vi blive nødt til at skrive vores eget. Det skriver jeg mere om i afsnittet Skriv jeres eget test framework.
Test først: Ved at skrive testprogrammerne før vi programmerer den egentlige funktionalitet, får vi størst mulig glæde af dem. Dels bidrager de til vores forståelse for den funktionalitet vi skal programmere. Dels kan vi få øjeblikkelig feedback på om der er fejl i vores løsning.
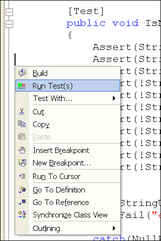
IDE-integration: Gør det så let som muligt for den enkelte udvikler at køre testprogrammer. Lad det gerne kunne foregå med et enkelt tryk på en tast eller en toolbar i det udviklingsværktøj udvikleren bruger til at skrive kode i. Herunder er et billede fra Visual Studio.NET udvidet med NUnitAddin, hvor vi kan afvikle den NUnit test case som markøren står i ved at højreklikke og vælge "Run Test(s)" fra menuen:
Kør alle tests hver nat: Værdien i en samling testprogrammer ligger ikke i at have skrevet dem. Værdien ligger i at få dem kørt igen og igen, så vi er hele tiden kan være sikre på at vores software er velfungerende. Den letteste måde at opnå dette på, er at etablere et baggrundsjob der kører alle testprogrammer igennem hver nat. Vi vil gerne opnå at denne natlige test stort set altid kører fejlfrit igennem, og derfor kører vi også en større delmængde af testprogrammerne inden vi lægger ny kode ind i vores versionskontrollerede repository.
Rapportér testresultater: Det skal være let for udviklerne at se resultatet fra den seneste kørsel af alle testprogrammer. Det kan enten ske ved at der udsendes en rapport som en email til alle udviklere, eller rapporten kan lægges et synligt sted på intranettet, eller fx som et desktop element. Her er et eksempel på en sådan rapport taget fra NUnit2Report, der danner en HTML-rapport udfra resultatet af en kørsel af en samling NUnit test cases:
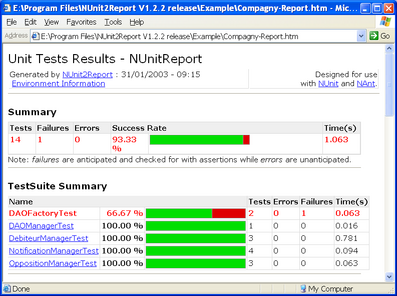
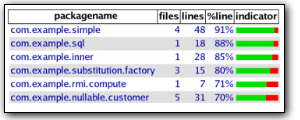
Kend dækningsgraden: Når vi har skrevet en masse testprogrammer, og kan se at de alle sammen kører igennem uden fejl stort set hver nat, så kan vi føle os rimeligt trygge ved den kode der bliver skrevet. Men hvor trygge kan vi egentlig tillade os at være? Er der nu også testprogrammer nok? Bliver vores kode testet så grundigt som vi forventer? Vi kan formulere hvor grundigt vores kode bliver testet ved at måle hvor stor en dækningsgrad testen giver os. Dækningsgraden er et udtryk for hvor stor en andel af vores kode der bliver gennemkørt i kraft af testprogrammerne. På mange udviklingsplatforme findes der udmærkede værktøjer til at måle dækningsgraden, men hvis sådan et værktøj ikke findes, må man nøjes med sin fornemmelse eller ad-hoc stikprøver. Her er et eksempel på en rapport fra værktøjet jcoverage, der kan måle dækningsgrad for Java-programmer:
Unit test - systemtest - integrationstest
Unit test er den form for test, hvor vi tester om systemets interne opbygning er som vi forventer. Vi tester vores komponents interface, så vi ved at den fungerer sådan som andre dele af koden forventes at bruge den.
Systemtest er den form for test, hvor vi tester om systemet lever op til brugernes forventninger. Vi tester om vores system implementerer den rigtige funktionalitet.
Man kan formulere det lidt slogan-agtigt ved at sige at unit testen tester om vi gør tingene rigtigt, mens systemtesten tester om vi gør de rigtige ting.
Når vi skriver unit tests kan vi vælge mellem at teste vores unit i isolation, eller udføre integrationstest. Ved test af en unit i isolation, sørger vi for at vores unit ikke kalder videre til de andre units i systemet den benytter, således at kun den pågældende unit bliver kørt. Ved integrationstest sørger vi for at vores unit faktisk kalder videre til de andre units i systemet den benytter.
Der er to fordele ved at teste units i isolation. For det første kan vi være næsten helt sikker på at en fejlende test skyldes en fejl i den pågældende unit, og ikke en fejl et helt andet sted. For det andet vil en sådan test som regel være langt hurtigere at køre end en integrationstest. Det betyder at udvikleren vil være tilbøjelig til at køre testen oftere eller at køre en større delmængde af alle tests under programmeringen.
Men det er ikke tilstrækkeligt at teste units i isolation. Hvis vi har to komponenter, A og B, så vil vores isolerede unit tests teste hvad man kan forvente sig af A og hvad man kan forvente sig af B. Men hvis A bruger B, er det jo ikke sikkert at A's forventning til B er sammenfaldende med den forventning vi tester, når vi tester B. Det vil derfor være nyttigt at supplere de isolerede unit tests med nogle integrationstests, hvor det sammenhængende system testes. Eftersom systemtest nødvendigvis også er integrationstest kan vi opnå automatiserede integrationstests ved at automatisere dele af systemtesten, typisk ved at teste direkte mod brugergrænsefladen.
Hvad er en unit?
En unit er en afgrænset del af koden, som resten af systemet benytter gennem et veldefineret interface. Det kan fx være:
- en klasse
- en funktion
- en stored procedure
- en webside
- et vindue
- en web service
En unit test sikrer at interfacet virkelig er veldefineret.
Grundlæggende unit test
I bunden af vores softwarehierarki har vi ofte en række simple units, som ikke har nogen afhængigheder til andre units. Disse units kan vi let teste i isolation. Eksempler på sådanne units er:
- datoklasse
- funktioner til strengmanipulation
- XML-parsning
Her følger et simpelt eksempel på en testcase for en datoklasses
parse()-metode:
gxDate d;
d.parse("2003-11-03");
CPPUNIT_ASSERT_EQUAL(gxDate::DatePrecision, d.getPrecision());
CPPUNIT_ASSERT_EQUAL(2003, d.getYear());
CPPUNIT_ASSERT_EQUAL(11, d.getMonth());
CPPUNIT_ASSERT_EQUAL(3, d.getDay());Komplekse datatyper
Men hvad så når vores unit benytter sig af komplekse datastrukturer som input eller output parameter? Det kan let blive sådan at det meste af vores testcase kommer til at gå med at initialisere inputparametre og gennemløbe strukturen af output parametre for at kunne assert'e på enkeltdele. Eksempler på sådanne datastrukturer er:
- Objekter fra forretningslaget, fx Faktura, Konto
- XML-dokumenter
- En query-definition
Hvordan undgår vi at vores testcase selv bliver kompleks?
Først og fremmest kan vi benytte de samme refaktoreringsteknikker til vores testprogrammer som vi benytter til vores produktionskode. Så i stedet for at bruge ti linier på at oprette et Faktura-objekt, så refaktorér ved hjælp af "extract method" til en hjælpefunktion, der opretter et Faktura-objekt ud fra et kunde-ID og et vare-ID. Det gør det også enklere at tilrette testcases, når Faktura-objektet får indført en ny egenskab, der skal sættes inden den kan bruges.
En anden metode er at benytte serialiserede udgaver af datastrukturen og lægge input og output som filer ved siden af testprogrammet. Dels vil de samme input-filer måske derved kunne genbruges af andre testprogrammer. Dels får man gjort selve testcasen meget kortere.
Endelig kan man udarbejde særlige udgaver af testframeworkets
AssertEqual()-metoder som selv kan arbejde sig rekursivt ned
igennem den komplekse datastruktur og sammenligne gren for gren og
give en præcis beskrivelse af hvor en eventuel forskel optræder.
Her følger et eksempel, hvor alle tre løsningsmetoder er i
anvendelse. Denne test case, tester at en bestemt XSLT-transformation
fungerer som den skal. Input-dokumentet er et XML-dokument, som
indlæses fra en fil. Et XML-dokument indeholdende det forventede
output indlæses også fra en fil. For at sikre at filerne kan indlæses
både når testen køres fra udviklingsmiljøet og når testen køres om
natten på byggemaskinen, benyttes hjælpefunktionen
StdTestFilePath(). Endelig er der udviklet en
AssertEqualsXml()-funktion, som kan sammenligne to
XML-dokumenter.
XmlDocument input = XmlUtil.Load(StdTestFilePath("mht-creator-input.xml");
XmlDocument result = XsltUtil.Transform("mht-creator.xslt", input);
AssertEqualsXml(StdTestFilePath("mht-creator-expected-output.xml"), result);Afhængighed af andre units
Men hvad nu, når vores unit benytter sig af andre units? Så skal alle disse andre units først initialiseres, og resultatet af at kalde metoder på vores unit kan måske kun ses ved at inspicere tilstanden på andre units. Med mindre vi altså kan teste vores unit i isolation.
Forudsætningen for at vores unit kan testes i isolation, er at denne unit er løst koblet fra de andre units den er afhængig af. Det betyder fx at en reference til et andet objekt ikke må være typet direkte med klassen på det andet objekt, men istedet være typet med et generelt interface som det andet objekt implementerer.
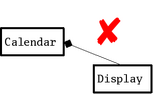
Prøv at se på følgende eksempel på en Calendar-klasse, som
vi gerne vil teste. Denne klasse repræsenterer en kalender-applikation
i en mobiltelefon, og når en aftale indtræffer skal den vise en besked
på mobiltelefonens skærm og den skal derfor referere til et
Display-objekt. Når disse to klasser er tæt koblede så ser
diagrammet ud på følgende måde, og så er det næsten umuligt at teste
Calendar-klassen i isolation:
Hvis vi istedet indfører et Calendar::Listener-interface
som Display-klassen implementerer og lader
Calendar-klassen referere til et vilkårligt objekt som
implementerer Calendar::Listener-interfacet, så opnår vi en
løsere kobling, og så findes der en måde, hvorpå vi kan teste
Calendar-klassen i isolation. Vi kan nemlig lade vores test
case, CalendarTest, implementere det samme
Calendar::Listener-interface, og initialisere
Calendar-objektet med en reference til
CalendarTest-objektet. På diagramform ser det således ud:
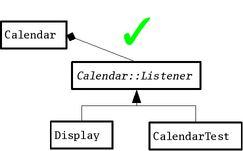
Koden til Calendar-klassen ser ud som følger:
class Calendar {
public:
class Listener {
public:
virtual void alarm(std::string event) = 0;
};
public:
void addListener(Listener*);
void addAppointment(std::string event, std::string time);
void setTime(std::string time);
private:
// ...
};Og koden til CalendarTest-klassen ser ud som følger:
class CalendarTest : public CppUnit::TestFixture, public Calendar::Listener {
void testCalendar() {
Calendar calendar;
calendar.addListener(this);
std::string event = "lunch";
calendar.addAppointment(event, "12:00");
calendar.setTime("11:55");
CPPUNIT_ASSERT(!_alarmFired);
calendar.setTime("12:00");
CPPUNIT_ASSERT(_alarmFired);
CPPUNIT_ASSERT_EQUAL(_alarmEvent, event);
}
void alarm(std::string event) {
_alarmFired = true;
_alarmEvent = event;
}
};Afhængighed til databaser
Men hvad nu, når vores applikation kører oven på en database? I dette afsnit præsenterer jeg to forskellige måder at håndtere test mod databaser på. I det første scenarie må alle udviklere deles om en fælles testdatabase; i det andet scenarie kan hver udvikler have sin egen testdatabase, hvilket giver en række fordele. Efterfølgende kommer der et afsnit om etablering af testdata og om test med store datamængder.
Når alle deles om den samme database
På nogle udviklingsprojekter er det ikke praktisk muligt at give hver udvikler sin egen testdatabase. Dette er ofte tilfældet med fjerdegenerations-værktøjer, hvor applikationsudvikling og databaseudvikling er én og samme ting, og hvor der ikke er faciliteter til versionsstyring og isoleret udvikling.
Her må vi udnævne en databaseinstans til brug for unit test. Denne databaseinstans kan enten køre på en fælles databaseserver eller på en server dedikeret til unit test databasen. Opret også en eller flere særlige unit test-brugere. Alle testprogrammer skal så forbinde sig til denne unit test-databaseinstans som en af unit test-brugerne.
Eftersom flere forskellige udviklere kan køre tests samtidig mod denne ene unit test-database skal vi overholde nogle spilleregler når vi skriver vores testprogrammer:
-
For det første må hver testcase starte med at oprette de testdata, som applikationen skal ændre på i løbet af testen, således at hver kørende testcase i princippet arbejder på sit helt eget testdatasæt. På den måde kan samtidig kørsler af forskellige test cases ikke ødelægge noget for hinanden.
-
For det andet må hver testcase tolerere andre testdata end dem testcasen selv har oprettet. En test case kan fx ikke antage at der findes et bestemt antal kunder i databasen, for andre test cases kan have oprettet nye kunder. I stedet må man nøjes med at fremsøge de kunder testcasen selv starter med at oprette, foretage sin test, og sammenholde resultatet med det først fundne antal kunder.
Her følger et eksempel på et testprogram, skrevet i C# med NUnit som tester en C++ komponent, der kører mod en Oracle database. Testprogrammet tester at komponenten fletter data fra databasen ind i en template på den rigtige måde:
// setup test data
FieldList sag = OpretSag("Julefrokost på slottet");
sag.create(autoCommit);
FieldList akt1 = OpretAkt(sag.systemKey);
akt1.create(autoCommit);
FieldList akt2 = OpretAkt(sag.systemKey);
akt2.create(autoCommit);
// perform merge
FieldList akt = createFieldList("akt");
akt.addField("sager:sagslbnr", sag.systemKey, validateNo);
Template template = akt.createTemplate(templatePath);
string xmlResult = template.merge(2);
// verify result
AssertEqualsFileString(expectedPath, xmlResult);Det er dog ikke uden vanskeligheder at være mange udviklere om en fælles database. En test der tester at fremsøgning virker som forventet vil typisk starte med at lave en fremsøgning ud fra et bestemt søgekriterie, derefter tilføje et velkendt antal poster (måske både nogen der matcher søgekriteriet og nogen der ikke gør), og derefter gentage fremsøgningen og sammenholde antallet med den første fremsøgning. Dette vil kun fungere hvis der ikke samtidig er en udvikler der starter en test der tilfældigvis opretter poster der matcher søgekriteriet. Den eneste måde at undgå dette på er at alle oprettelser gøres helt unikke for den pågældende session, fx ved at lade udviklerens brugernavn eller et tilfældigt tal indgå i de data som man opretter og som indgår i søgekriteriet.
Det største problem ved at være mange udviklere om en fælles database er dog at én udviklers ændringer til strukturen af databasen kan forhindre andre udviklere i at køre deres test fordi strukturændringen kræver opfølgende ændringer i koden. Jeg har set mange projekter der har kørt på denne måde, hvilket ofte har forhindret udviklerne i at køre tests i halve og hele dage.
Når hver har sin egen database
For at undgå de før nævnte problemer kan man sørge for at hver udvikler kører sin egen unit test database instans, typisk på sin egen udviklermaskine. For at få det til at fungere må man sørge for at ændringer til databasen let kan fordeles ud til samtlige udviklere. Den letteste måde at gøre dette på er at sørge for at hele databasen kan oprettes ud fra en række SQL-scripts. Ændringer til databasen foregår ved at ændre i disse SQL-scripts. Og vi får opdateret vores egen database ved at hente og køre de nyeste SQL-scripts fra vores versionskontrollerede repository på præcis samme måde som vi henter den nyeste version af koden. Disse SQL-scripts bliver simpelt hen en del af koden på lige fod med resten af applikationen, hvilket i sig selv øger kvaliteten af den samlede versionskontrol.
Et simpelt script, der gendanner en database ud fra et SQL-script, ser for databasesystemet SQLite således ud:
$ rm -rf $(DBPATH)
$ sqlite $(DBPATH) < CreateTables.sqlSQL-scriptet CreateTables.sql indeholder
kommandoer til at oprette tabeller, index, etc, i stil med:
create table Products (
ProductId integer not null primary key,
ProductName varchar(50),
UnitPrice decimal(10,2)
);Testdata
Men når hver eneste test case skal oprette sine egne testdata, så får vi hurtigt et stort vedligeholdelsesproblem med alle disse testdata. Og så må vi jo hive fat i refaktorerings-værktøjskassen igen. Find frem til de test data som mange test cases opretter uden at have brug for at ændre i dem; det vil typisk være stamdata som fx kunder og varetyper men også standardiserede kernedata som fx sager eller ordrer. Vi kan udnævne disse data til standard testdata, og gøre alle vores testprogrammer simplere ved at lade dem referere til disse standard testdata. Eneste regel er at testprogrammer ikke må ændre i disse standard testdata; vi skal altid kunne regne med at de er i deres oprindelige stand.
Og på samme måde som vi scriptede os til oprettelsen af hver udviklers database, så scripter vi os også til indlæggelsen af standard testdata, som her hvor SQL-scriptet indeholder en kommando til indlæggelse af en standard test-ledetekst:
insert into ledetekst (
type, ledetxt, ledesyno, text, rutine, system)
values (
'AP', 'UTAdvokat', 'UTADV', 'Advokat', '', '');Og så sørger vi for at disse standard testdata indlægges samtidig med oprettelsen af databasen:
$ sqlite $(DBPATH) < LoadTestData.sqlStore datamængder
Men hvad så når vi har brug for store, og gerne realistisk
udseende, datamængder til fx test af søgetider? Det er jo ikke
praktisk muligt at sidde og skrive en million forskellige
insert-statements i LoadTestData.sql.
En simpel ting man kan gøre er at lave et lille program, der
genererer en million forskellige insert-statements og skriver dem i en
.sql-fil som kan indlæses i databasen. Et sådant program kan
fx se således ud:
import java.util.Random;
public class GenerateOrders {
public static void main(String[] args) {
Random random = new Random();
for(int i = 0; i < Integer.parseInt(args[0]); ++i) {
System.out.println("insert into order (id, customer, item, quantity) values (");
System.out.println(" " + (i+1) + ", ");
System.out.println(" " + random.nextInt(10) + ", ");
System.out.println(" " + random.nextInt(500) + ", ");
System.out.println(" " + random.nextInt(8) + " ");
System.out.println(");");
}
}
}Dette program skal så køres som et ekstra step i forbindelse med at databasen oprettes:
$ GenerateOrders 1000000 > LoadOneBillionOrders.sql
$ sqlite $(DBPATH) < LoadOneBillionOrders.sqlDet kan også være vi er så heldige at have en eksisterende variant af systemet, som allerede har været i drift i en længere periode. For så kan vi udtrække rigtige data fra dette system og herudfra lave et script som indlægger disse data i vores database. Hvis det eksisterende system også kører på en SQL-database, kan man lave et SQL-script der trækker data ud og danner et SQL-script til at lægge data ind, som i det følgende eksempel:
select
'insert into products
(ProductId, ProductName, UnitPrice)
values (' ||
ProductId ||
', ''' || ProductName ||
''', ' || UnitPrice || ');'
from products;Dette script kan vi køre en gang for alle og gemme outputtet i
LoadSampleProducts.sql:
$ sqlite $(OLD_SYSTEM_PATH) GenerateSampleProducts.sql > LoadSampleProducts.sqlLoadSampleProducts.sql lægger vi så i vores
versionskontrollerede repository, og sikrer at det bliver kørt hver
gang vi genbygger en database:
$ sqlite $(DBPATH) < LoadSampleProducts.sqlAfhængighed til eksterne systemer
Men hvad nu når vores applikationer integrerer til eksterne systemer som er mere eller mindre uden for vores kontrol? Der findes mange forskellige former for integrationer, nogle af de almindeligste er:
-
Data udveksling: Vores applikation importerer data fra det eksterne system eller eksporterer data til det eksterne system. Et eksempel kan være en web-butik, der importerer produktoplysninger fra virksomhedens ERP-system.
-
Data synkronisering: Data fra vores applikation og data fra det eksterne system holdes synkroniserede, således at ændringer det ene sted også foretages det andet sted. Et eksempel kan være deling af brugerprofil-oplysninger mellem flere forskellige systemer, således at brugeren kun behøver rette sine oplysninger i et af systemerne.
-
Konversationsorienteret: Vores applikation foretager visse beregninger eller dataopslag ved at sende forespørgsler til det eksterne system. Eksempel herpå er web-services som Google, DMI eller Amazon.
-
Hændelsesorienteret: Vores applikation afleverer resultatet af en operation til det eksterne system. Et eksempel kan være en bestilling, der afsluttes med at der sendes en bekræftelses-email til brugerens mailsystem.
Som man kan se er variationen i eksterne systemer stor, og der er også stor forskel på hvor megen kontrol vi har over det eksterne system. Jo mere kontrol vi har over det eksterne system, jo lettere kan vi tilrettelægge vores test på den mest hensigtsmæssige måde selvom det kræver ændringer i det eksterne system.
Der er to udfordringer i at teste integrationen mellem vores system og det eksterne system. Dels må vi sikre entydighed i kommunikationen, således at givne forespørgsler til det eksterne system altid give de samme resultater. Og dels må vi have mulighed for at inspicere det eksterne system for at afgøre om vores applikation sender korrekte data til det eksterne system.
Udfordringerne mødes i større eller mindre grad alt efter hvilken løsning vi vælger. Vi kan enten integrere mod en testudgave af systemet; vi kan teste mod produktionssystemet eller vi kan teste mod et simuleret system.
Integrer mod et testsystem
Ofte er det muligt at integrere mod en testudgave af det eksterne system i stedet for at køre mod produktionsudgaven. I testudgaven kan vi lave en aftale med den eksterne part om at testudgaven indeholder bestemte testdata, som vi benytter når vi tester fra vores side. Vi kan opfordre den eksterne part til at scripte disse standard testdata, således at de hurtigt kan gendannes, sådan som jeg beskrev det ovenfor i kapitlet om databaser. For eksempel har CPR-registeret et særligt testsystem, som man kan integrere mod mens man har brug for at teste.
Integrer mod produktionssystemet
Somme tider får man ikke mulighed for at køre mod en testudgave, men må i stedet køre mod produktionsudgaven. Dette sker ofte ved "read-only" integrationer, hvor der ikke ændres oplysninger i det eksterne system. Af samme grund får får man som regel ikke lov til at indlægge særlige testdata i produktionsudgaven. I stedet må man aftale hvilke produktionsdata, der er så stabile (dvs ændres så sjældent) at vi kan bruge dem som standard testdata.
Integrer mod et simuleret system
Hvis man gerne helt vil undgå afhængighed af eksterne parter, er der ingen anden udvej end at simulere det eksterne system. Denne løsning er helt i tråd med at teste units i isolation. Simuleringssystemet skal naturligvis have samme grænseflade som det rigtige eksterne system, men derudover kan man fokusere på at få det til at håndtere standard testdata.
Man kan bruge en slags simulering til at teste at email-afsendelse sker som forventet. Her gælder det om at vælge en mailserver som vi kan tilgå fra et testprogram. Det kan enten være den mailserver man anvender internt i organisationen, hvis det er let at lave et program der checker mail på den. Alternativt kan det være en offetlig tilgængelig mailserver, der har indbygget webmail, som fx Yahoo, idet man her kan lave et testprogram ved hjælp af jWebUnit, der kan checke om en mail er nået frem. På den valgte mailserver opretter man så et antal testmail-konti og benytter disse kontis mailadresser som en del af standard testdata. Testprogrammet må være lavet sådan at det venter et passende stykke tid, og derefter checker om den forventede mail er nået frem.
Eksempel
Her følger et eksempel på integration mod et eksternt system. Min applikation er her en børnevenlig søgeportal. Selve søgningen udføres ved hjælp af Google, som dermed er det eksterne system i eksemplet. Jeg integrerer direkte mod Googles produktionssystem, og har derfor ikke mulighed for at indlægge standard testdata. Testprogrammet tester at vores applikation konfigurerer Google korrekt, således at søgeresultatet bliver præsenteret med danske tekster, og således at der kun er blevet søgt på danske websites. Testprogrammet er skrevet i Java med jWebUnit og ser ud som følger:
// enter site
getTestContext().setBaseUrl("http://www.some-site.dk/");
beginAt("portal.html");
// verify site
assertTitleEquals("Børnenes Internet");
// perform search
gotoFrame("top");
setFormElement("q", "warhammer");
submit();
// verify result
gotoFrame("body");
assertTitleEquals("Google-søgning: warhammer ");
assertTextPresent("warhammer.dk");
assertTextNotPresent("www.games-workshop.com");Her har jeg udnævnt søgeudtrykket "warhammer" som standard
testdata sammen med søgeresultaterne "warhammer.dk" og
"www.games-workshop.com" ud fra en formodning om at disse
data er tilstrækkelig stabile til at testen ikke pludselig fejler pga
ændringer i Googles søgedatabase.
Afhængighed til specifik hardware
Men hvad nu når vores unit kun kører på en selvstændig hardwareenhed, og ikke på den PC som vi sidder og udvikler på? Hvordan skal vi så få afviklet vores test automatisk hver nat? Og hvis opgaven som vores unit løser involverer input fra og styring af mekaniske enheder som fx sensorer, pumper, ventiler eller temperaturregulatorer hvis opførsel kun er styret af den omgivende fysiske virkelighed, hvordan opstiller vi så vores testcases?
Ofte er man nødt til at lave en decideret testopstilling, hvor det er muligt at påvirke de fysiske omgivelser på en forudsigelig måde og derefter teste at vores unit opfører sig som den skal. Det kan fx gælde hvis vores unit skal indgå i et apparat der skal godkendes af en offentlig myndighed. Hvis vores unit tager input fra en temperatursensor, må testopstillingen bestå af en slags køle- eller varmeskab hvor temperaturændringer kan gennemføres. I sådanne scenarier vil testcasen først indstille testopstillingen til at opføre sig på en bestemt måde med fx en starttemperatur og planlagte temperaturændringer over testforløbet. Derefter startes vores unit, og vi tester at vores unit opfører sig om den skal under disse temperaturforhold.
Somme tider kan slippe af sted med en simplere løsning, nemlig at simulere de mekaniske enheder. Her er der så igen tale om et eksempel på at vi tester vores unit i isolation. Vi sørger for at vores unit kommunikerer med de mekaniske enheder gennem et veldefineret interface, og skriver en simulator, der opfylder det samme interface. Denne simulator kan passende laves så den indlæser et script, der angiver hvornår og hvordan de forskellige mekaniske enheder skal agere, og vi kan derefter lave en testcase som initialiserer simulatoren med et passende script og derefter tester at vores unit opfører sig som forventet.
Hvis vi gerne vil afvikle vores unit og vores testcase på den selvstændige hardwareenhed, så kan det ofte lade sig gøre ved brug af den debugger vi i forvejen benytter. Debuggeren kan startes fra et script og få besked om at downloade kode og testprogram til hardwareenheden og bagefter starte afviklingen og opsamle output i en fil, som man så efterfølgende kan sammenligne med et forventet output.
Eksempel
Her følger et eksempel på hvorledes dette gøres med debuggeren MULTI fra Green Hills Software.
Debuggeren startes med følgende parametre: den oversatte unit
(TcpTest) og en fil med kommandoer til
debuggeren. Efterfølgende sammenlignes outputtet med det forventede
output:
$ multi TcpTest -p TcpTest.cmd
$ fc TcpTest.expected.out TcpTest.actual.outKommandofilen TcpTest.cmd ser ud som følger:
breakpoint OnAssertLoop
breakpoint OnTestEnded
restart > TcpTest.actual.out
wait
quit all
Kommandoerne sikrer
- at testprogrammet startes, og at output fra testprogrammet gemmes i en fil (linie 3)
- at testafviklingen stoppes når testen er slut selvom programmet som sådan ikke standser (linie 2)
- at testafviklingen stoppes hvis der indtræffer en fejlsituation, her i form af en fejlende assert, det kunne også være i form af en exception (linie 1)
- og endelig at testafviklingen ikke stoppes før en disse situationer indtræffer (linie 4)
Test af brugergrænseflade
Men hvad nu når vores unit er en del af brugergrænsefladen? Hvordan får vi testprogrammet til at klikke på knapperne og afgøre at dialog-layoutet og feltindhold er som forventet?
Først og fremmest vil jeg gøre det klart at brugergrænseflade måske er den eneste del af systemet vi undlader at teste automatisk. Årsagen er den simple, at vi alligevel er nødt til at teste brugergrænsefladen manuelt, fordi en lang række, typisk ikke-funktionelle, aspekter ved brugergrænseflader kun kan testes manuelt:
-
Er de beskrivende tekster på skærmbilleder, menuer og fejlmeddelelser meningsfulde?
-
Er den visuelle opsætning af skærmbilledet intuitiv i forhold til de opgaver der skal løses?
-
Er de forskellige skift mellem skærmbilleder i komplicerede arbejdsgange fornuftige?
-
Reagerer systemet tilstrækkelig hurtigt på brugerinput som fx at holde en af piletasterne nede?
-
Er det visuelle indtryk tilstrækkelig "lækkert"?
-
Reagerer systemet hensigtsmæssigt på uventet input (slå-hånden-i-tasturet-testen)?
Hvis vi skal undlade at autoteste brugergrænsefladen er det naturligvis vigtigt at der er en klar adskillelse mellem brugergrænseflade-units og funktionelle units, således at det lag der ikke testes er så tyndt som muligt, og således at de funktionelle units kan testes automatisk.
Når der opdages en fejl i forbindelse med den manuelle test, og når denne fejl viser sig ikke at skyldes fejl i brugergrænseflade-koden, så er det vigtigt, at vi opretter en automatiseret test mod den fejlende funktionelle unit, og ser at den fejler, inden vi giver os til at rette fejlen.
Hvis brugergrænsefladen er web-orienteret (HTTP-baseret), så findes der udmærkede unit test frameworks der gør det let at skrive deciderede unit test cases, der tester websiderne, fx NUnitAsp til .NET og jWebUnit til Java. I forrige afsnit om test mod eksterne systemer, viste jeg et eksempel på en jWebUnit test case.
I visse tilfælde stilles der så store krav til at
brugergrænsefladen er velfungerende, at det godt kan betale sig at
investere i at automatisere brugergrænsefladetesten. Og så viser det
sig heldigvis at det oftest sagtens kan lade sig gøre. En grafisk
brugergrænseflade vil typisk være repræsenteret ved en række objekter,
som testprogrammet kan tilgå: Der vil være Dialog-objekter,
Panel-objekter, Button-objekter og
TextBox-objekter. Feltindhold kan aflæses med en
getText()-metode, knapper kan klikkes med en
click()-metode. Her følger et eksempel på en testcase, der
tester at der skrives "OK" i vinduet, når man udfylder feltet med et
tal og klikker på knapen. Eksemplet tester kode skrevet i C++ med MFC
til Windows og benytter testframeworket CppUnit:
// precondition
dlg->GetDlgItemText(IDC_CODETESTRESULT, text.m_str);
CPPUNIT_ASSERT_EQUAL(CComBSTR(""), text);
// enter text and click
dlg->SetDlgItemText(IDC_CODEEDIT, _T("1234"));
dlg->SendDlgItemMessage(IDC_CODETESTBUTTON, BM_CLICK);
// verify result
dlg->GetDlgItemText(IDC_CODETESTRESULT, text.m_str);
CPPUNIT_ASSERT_EQUAL(CComBSTR("ok"), text);
// cleanup
dlg->PostMessage(WM_COMMAND, IDOK);Eksisterende kode
Hvad stiller vi op med al den eksisterende kode: Er vi nødt til at skrive automatiseret test for det hele, før vi kan autoteste på den nye kode? Svaret afhænger af, om vi skal lave et nyt modul, eller skal rette rundt omkring i den eksisterende kode.
Hvis vi skal udvikle et nyt modul til et eksisterende system, kan vi programmere automatisk unit test til det nye modul. Det kræver at modulet bliver programmeret, så det er løst koblet med den gamle kode: Der skal være en veldefineret grænseflade, hvor modulerne kender hinanden ved hjælp af interfaces og ikke direkte på objekt- eller funktionsnavne. På den måde kan vi skrive unit tests, der tester de nye komponenter isoleret fra den gamle kode.
Hvis vi står med et eksisterende system og skal lave en ny release med fejlrettelser og funktionalitet spredt rundt i koden, er det sværere at lave meningsfulde unit tests. Her vil det være mest nyttigt at skrive automatiske integrationstests, ikke som isolerede unit tests, men som tests for hver af fejlrettelserne og de nye features. Inden man går igang med en fejlrettelse, skriver man en automatisk test for netop denne fejl. Testen vil formentlig kalde ned igennem mange lag af funktionalitet, måske helt ude fra brugergrænsefladen. Så længe man kun har få automatiske tests er man ikke sikret mod følgefejl, og de giver ikke så præcis og dækkende test af koden. Men de lægger grunden til et sæt af automatiske tests, som efterhånden vil give en større og større sikkerhed mod følgefejl.
At starte med automatiseret test på et nyt modul eller en lille udvidelse til et eksisterende system, kan også være en sikker ramme for udviklerne i at lære at arbejde med automatiseret test. I den situation er systemets virkemåde, kodens struktur og værktøjerne velkendte, så det eneste nye udviklerne skal lære, er at arbejde med automatisering af tests. Den erfaring kan derefter være et godt udgangspunkt for at starte et nyt projekt med fuld udnyttelse af automatiseret unit test.
Test af multithreaded units
Men hvad nu når vores unit benyttes samtidig af flere tråder. Hvordan tester vi at disse tråde bliver synkroniseret korrekt af vores unit? Hvordan opstiller vi en testcase der kører som flere tråde?
Vores testcase kan starte hjælpetråde op, og lade disse hjælpetråde
kalde vores unit. Ved hjælp af semaforer kan man få selve
testprogrammet til at vente på at hjælpetrådene kører til ende. Benyt
også gerne en timeout-mekanisme, således at testen ikke hænger hvis én
af hjælpetrådene fejlagtigt kører for evigt. De fleste unit test
frameworks er imidlertid ikke implementeret på en sådan måde at man
kan kalde Assert()-metoderne fra andet end
hovedtesttråden. Hjælpetrådene må derfor være programmeret sådan at
fejlsituationer opsamles i resultatvariable, som hovedtesttråden så
kan assert'e på, når hjælpetrådene er færdige.
Hvis vores unit har en kritisk region, som flere tråde ikke må befinde sig i samtidig, så er det vigtigt at teste at vores unit benytter synkroniseringsmekanismerne korrekt til at sikre dette. Det er imidletid ikke så let at teste dette, da fejl ofte kun viser sig under helt særlige og ureproducerbare timings-forhold. Den eneste realistiske måde at teste på, er at opstille en testcase der gentages et stort antal gange, på en sådan måde at timinigen af de enkelte trådes handlinger ændres ved hjælp af tilfældigt indlagte pauser.
Her følger et eksempel på en testcase, hvor vores unit
implementerer messaging mellem tråde. Vores testprogram får rollen som
klient og starter en hjælpetråd op som får rollen som server. Her kan
man se hvordan semaforen testCountCompleted bliver brugt til
at få testprogrammet til at vente på at hjælpetråden fuldfører sin
opgave indenfor en specificeret timeout. Serveren indeholder
bl.a. følgende følgende messagehandler:
void onCount() {
++counter;
if(counter == countRequestCount) {
send("TestCountCompleted");
}
}Testprogrammet erklærer semaforen, opfører sig som klient og indeholder en messagehandler der modtager svar fra serveren:
Semaphore testCountCompleted;
void testCount() {
for(int i = 0; i < countRequestCount; ++i) {
send("Count");
}
assert(testCountCompleted->get(2000) != TX_TIMEOUT);
}
void onTestCountCompleted() {
testCountCompleted->put();
}Refaktorering af testprogrammer
Men hvad nu når vi har fået skrevet en masse testprogrammer og det begynder at tage længere og længere tid at vedligeholde disse, så de compilerer og kører allesammen hver nat?
Først og fremmest må vi indstille os på at der vil være en vis vedligeholdelse. Når navne og parametre ændres og funktioner tilføjes og fjernes må ændringerne selvfølgelig også gennemføres i testprogrammerne. Som altid kan det være nyttigt at bruge et refaktoreringsværktøj til at lette dette arbejde.
I det hele taget skal vi ikke glemme at testprogrammer også er kode. Og alle de gode refaktoreringsvaner som vi følger for vores produktionskode, er lige så gode at følge for vores testprogrammer. Ofte er det fristende at lave en ny testcase ved at kopiere en eksisterende testcase og så lave et par passende tilretninger. Men så snart vi har to-tre næsten ens testcases, så er det tid til at finde refaktoreringsværktøjet frem og flytte de fælles dele ud i en hjælpefunktion: dels bliver selve testcase mindre og dermed lettere at gennemskue, dels vil den fremtidige vedligeholdelse også blive mindre.
Især de dele af testprogrammerne der tager sig af opsætning af inputdata og verificering af resultater er gode kandidater til at blive refaktoreret ud i hjælpefunktioner. Med tiden kan man ende med at få et helt bibliotek af hjælpefunktioner til brug i testprogrammer, måske ikke bare på det aktuelle projekt, men også nyttige på andre projekter.
Brugen af standard testdata, som beskrevet i et tidligere afsnit, er også et eksempel på refaktorering, idet oprettelsen af disse standard testdata foretages af et script én gang for alle inden testprogrammerne startes, og dermed slet ikke indgår som en del af testprogrammerne.
Sommetider har vi brug for en række ensartede testprogrammer, der tester den samme funktion med mange forskellige kombinationer af inputparametre. Her kan det være nyttigt at refaktorere hele indmaden af testprogrammet ud til et parametriseret testprogram. I begyndelsen har vi skrevet en lang række testfunktioner i stil med:
void testDivisionSimple() {
assertEquals(4, Math.Div(12, 3));
}
void testDivisionNegative() {
assertEquals(-1, Math.Div(-3, 3));
}Som refaktorering udtrækker vi et parametriseret testprogram:
void testDivision(int numerator, int denominator, int expectedQuotient) {
assertEquals(expectedQuotient, Math.Div(numerator, denominator));
}Dernæst kan vi forsimple vores testprogrammer:
void testDivisionSimple() {
testDivision(12, 3, 4);
}
void testDivisionNegative() {
testDivision(-3, 3, -1);
}Denne form for test kaldes også for data-drevet test, fordi man reelt opstiller en hel tabel over inputværdier og forventede outputværdier, og derefter lader testprogrammet gennemløbe denne tabel og teste alle de angivne kombinationer.
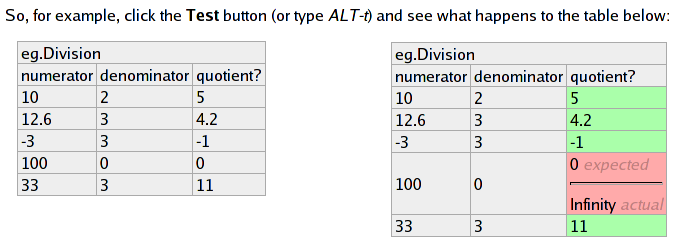
En af fordelene ved datadrevet test er at selve testspecifikationen udtrykkes så enkelt, at ikke kun udviklerne kan forholde sig til den, men også brugerne eller andre af kundens folk. Dermed kan udformningen af testspecifikationen gøres til et samarbejde mellem de personer der stiller kravene til systemet og dem der implementerer systemet. Et eksempel på et samarbejdsværktøj af denne type er Fitnesse, der tilbyder en webbaseret brugergrænseflade, hvor brugerne kan oprette og vedligeholde tabeller over testdata ved at redigere selve websiden på Wiki-manér. Med et enkelt tastetryk køres testen og tabellen farves med grønne og røde rækker alt efter hvilke testkombinationer der kørte igennem uden fejl. Her følger et eksempel på hvordan en Fitnesse test ser ud før og efter den er blevet kørt:
Skriv dit eget testframework
Men hvad nu, når der ikke findes noget testframework til den platform vi arbejder på? Til mange platforme, og i hvertfald til de mest udbredte platforme, findes der allerede testframeworks, ofte flere til den samme platform, og ofte både kommercielle og open source. Men ofte kommer man alligevel ud for en platform hvor det ikke er muligt at finde et tilgængeligt testframework.
I så fald bliver vi nødt til at skrive vores eget testframework, og heldigvis behøver dette ikke være nogen stor opgave. Selvfølgelig kunne man i princippet bruge lang tid på at tilføje avancerede features til ens eget testframework, men et grundlæggende anvendeligt testframework kan i de fleste tilfælde godt laves på et par dage.
Et testframework skal i det mindste opfylde følgende tre kriterier:
-
Der skal findes en mekanisme hvor testresultater kan opsamles under kørslen af testprogrammer
-
Der skal findes en række assert-metoder som kan benyttes fra testprogrammer.
-
Det skal være muligt at udtrække en rapport over de opsamlede testresultater.
For mange af de objektorienterede testframeworks, som fx JUnit, opsamles testresultater typisk i en objektbaseret datastruktur. Det er imidlertid ikke alle platforme, der er gearet til at holde store dynamiske datastrukturer i memory. Disse platforme er ofte knyttet tæt til en database, og i sådanne situationer kan det derfor være bedre at benytte databasen til at opsamle testresultater.
Som illustration vil jeg her vise de første spadestik til et testframework til økonomisystemet Navision fra Microsoft Business Solutions. Programmeringssproget i Navision hedder CAL og er et Pascal-agtigt sprog, der netop er knyttet tæt op til den tilhørende database.
Vi starter med at erklære den tabel i databasen som skal indeholde opsamlede testresultater:
OBJECT Table 99900 TESTRESULT
{
FIELDS
{
{ 1 ; ;ID ;Integer }
{ 2 ; ;NAME ;Text250 }
{ 3 ; ;MSG ;Text250 }
{ 4 ; ;SUCCEEDED ;Boolean }
}
KEYS
{
{ ;ID }
}
}Som den er erklæret her egner den sig kun til situationer hvor hver udvikler kører mod sin egen database. Hvis alle kører mod den samme database, må der tilføjes en kolonne med et TestSessionId, så samtidige kørsler ikke forstyrrer hinanden.
Inden vi kan starte en testkørsel, må vi fjerne tidligere testresultater. Dette laver vi en procedure til:
OBJECT Codeunit 99992 UnitTest
{
CODE
{
PROCEDURE TestInit@9();
VAR
testresult@1000 : Record 99900;
BEGIN
testresult.DELETEALL
END;
}
}Så har vi brug for en assert-funktion (på sigt flere). Disse funktioner kan vi senere kalde fra vores testprogrammer, og assert-funktionerne skriver deres resultatet i testresultattabellen:
OBJECT Codeunit 99992 UnitTest
{
CODE
{
PROCEDURE AssertEquals@2(n@1000 : Text[250];msg@1001 : Text[250];expected@1002 : Decimal;actual@1003 : Decimal);
VAR
fullmsg@1004 : Text[250];
BEGIN
fullmsg := msg;
fullmsg := fullmsg + ': expected ' + FORMAT(expected);
fullmsg := fullmsg + ', but was ' + FORMAT(actual);
AddTestResult(n, fullmsg, expected = actual);
END;
PROCEDURE AddTestResult@3(name@1000 : Text[250];msg@1001 : Text[250];succeeded@1002 : Boolean);
VAR
nextid@1003 : Integer;
testresult@1004 : Record 99900;
BEGIN
IF testresult.FIND('+') THEN
nextid := testresult.ID + 1
ELSE
nextid := 1;
CLEAR(testresult);
testresult.ID := nextid;
testresult.NAME := name;
testresult.MSG := msg;
testresult.SUCCEEDED := succeeded;
testresult.INSERT;
END;
}
}Når alle vores testcases er gennemløbet vil vi gerne have en rapport over resultatet. Følgende simple implementering giver en pop up-dialog for hver test, der er fejlet:
OBJECT Codeunit 99992 UnitTest
{
CODE
{
PROCEDURE TestReport@5();
VAR
testresult@1000 : Record 99900;
BEGIN
IF testresult.FIND('-') THEN
REPEAT
IF NOT testresult.SUCCEEDED THEN BEGIN
MESSAGE(testresult.NAME + ': ' + testresult.MSG);
END;
UNTIL testresult.NEXT = 0;
END;
}
}Database-orienterede platforme som Navision har dog udmærkede faciliteter til at lave rapporter, som med fordel kan benyttes til at lave rapporter, der kan printes ud eller sendes rundt på mail.
Nu har vi faktisk tilstrækkelig med faciliteter i vores simple testframework til at vi kan skrive en testcase. Her tester vi at beregning af gennemsnitlig service cost fungerer:
OBJECT Codeunit 99994 ServiceCostUtilTest
{
CODE
{
VAR
serviceCostUtil@1000 : Codeunit 99995;
UnitTest@1001 : Codeunit 99992;
n@1002 : TextConst 'ServiceCostUtilTest';
PROCEDURE AvgCost@1();
BEGIN
serviceCostUtil.Create('UNITTEST1', 10);
serviceCostUtil.Create('UNITTEST2', 20);
serviceCostUtil.Create('UNITTEST3', 30);
UnitTest.AssertEquals(n, 'avg', 20, serviceCostUtil.Avg('UNITTEST*'));
serviceCostUtil.Delete('UNITTEST3');
serviceCostUtil.Delete('UNITTEST2');
serviceCostUtil.Delete('UNITTEST1');
END;
}
}Og endelig kan vi samle det hele sammen i en testsuite, der sørger for at alle testcases bliver kørt:
OBJECT Codeunit 99993 AllTests
{
PROPERTIES
{
OnRun=VAR
UnitTest@1000 : Codeunit 99992;
ServiceCostUtilTest@1000 : Codeunit 99994;
BEGIN
UnitTest.TestInit();
ServiceCostUtilTest.AvgCost();
UnitTest.TestReport();
END;
}
}Det er klart at vi kan forbedre en del på ovenstående simple testframework, men det kan vi med fordel vente med at gøre til behovet opstår. Som det står nu er der faktisk funktionalitet nok til at komme igang med at skrive testcases.
Henvisninger
Der findes et par udmærkede bøger om unit test. Jeg synes den bedste er:
- "Unit Testing in Java" af Johannes Link
Kent Beck har skrevet en bog som især handler om test first teknikken, og bl.a. beskriver hvordan man udvikler et testframework test first.
- "Test Driven Development" af Kent Beck
En anden bog, der bl.a. omhandler testautomatisering for database-systemer, er:
- "Agile Database Techniques" af Scott W. Ambler
Jeg har omtalt en række open source test frameworks i denne artikel; de kan findes på følgende adresser:
- CppUnit på cppunit.sourceforge.net
- jcoverage på jcoverage.com
- JUnit på junit.org
- jWebUnit på jwebunit.sourceforge.net
- NUnit på nunit.org
- NUnit2Report på nunit2report.sourceforge.net
- NUnitAddIn på sourceforge.net/projects/nunitaddin
- NUnitAsp på nunitasp.sourceforge.net
- DbUnit på dbunit.sourceforge.net
- FitNesse på fitnesse.org
Sammenfatning
Når man giver sig i kast med automatiseret unit test på virkelige projekter vil man opdage at der er flere udfordringer end man umiddelbart får indtryk af ved læsning af artikler og bøger om emnet. Men som vi har vist i denne artikel findes der imidlertid enkle teknikker, som giver gode løsninger på problemerne. I praksis viser det sig, at den økonomiske værdi af automatiseret test i form af sparet tid, fleksibilitet og højere kvalitet overstiger den nødvendige investering.